-
[미]파이토치 DataParallel, DistributedDataParallel, apex + amp 정리파이토치&텐서플로우&관련코딩 2021. 6. 13. 14:47
ICCV KD rebuttal 때 이미지넷 요청을 받았었는데 시간이 없어서 찾아보고 적용.
먼저 정리하자면, 분산처리에는 2가지 방법이 있고 파이토치에서는 크게 DataParallel과 Distributed.DataParallel이 있다. 하지만 Distributed는 오류가 뜬다 하여 nvidia에서 제공하는 apex를 썼다.
예를 들어 배치가 128이고 resnet101을 훈련시킨다고 하자. 속도의 향상, 또는 VRAM의 부족으로 인해 분산처리를 이용하여 훈련하려고 한다. 서버 컴이 다 돌아가고 있어서 순서 설명은 GPU4개를 이용하는 것으로 설명하였고, 실제 코드는 확장성을 위해 GPU는 4개중 0,1,3 3개를 이용하는 것으로 구현하였다. 기준 GPU는 0.
1. DataParallel
1. 배치를 32씩 4개의 GPU에 할당한다.
2. resnet101 모델 전체를 각 GPU에 복사한다.
3. 각 GPU에서 32개의 배치를 Forward 한다
4. 나온 output을 기준 GPU3에 모은다.
5. GPU3에서 각 GPU에서 나온 output을 이용하여 각 batch 32개에 대한 loss를 계산
6. loss를 다시 각 GPU에 scatter한다.
7. 각 GPU가 gradient를 계산하고
8. GPU3에 모아서 모델 업데이트.
아래 그림과 같다.

문제는 이렇게 하면 GPU3이 메모리를 순간적으로 많이 먹게 되어 터질 위험이 있다. 하지만 가장 간편하고 빠른 방법이다. 아래 코드를 참고.


주목할 점은 기준 0번 GPU가 더 많이 VRAM을 잡아 먹는 것과 PID가 모두 같다는 것이다.
2. Distributed DataParallel
이 개념이 약간 생소했음. [미결] 이 알고리즘은 각 GPU마다 똑같이 복제된 모델이 어떻게 기준 GPU로 정보를 업데이트 하는지 완전히 이해를 못했다.
용어 및 개념 정리
* 여러 GPU를 사용할 때 서버 전체를 쓰면 좋겟지만 그렇지 못할 경우 GPU를 지정해 주어야 한다. 그럴때 쓰는 것이 os.environ["CUDA__VISIBLE_DEVICES"]로 이 머신(노드)에서 몇 번 GPU를 사용할 것이다 라고 명시.
* local rank : 프로세스를 구분하기 위해 가장 많이 사용하는 변수. 이 변수는 cmd창에서
python -m torch.distributed.launch --nproc_per_node=3 main.py 를 실행할때 각 프로세스별 순위를 정하는 것이다. 그래서 코드에 명시한 것처럼 local_rank를 출력해보면 0,1,2가 랜덤으로 다르게 출력되는 것을 볼 수 있다. 또한 local rank는 GPU와 무관하게 반드시 0부터 시작되는 것을 기억하자. 즉 아래 코드에서는 GPU를 0,1,3을 쓰므로 rank가 1,2,0으로 출력이 되었을 때, 첫번째 프로세스에서는 GPU 1을 쓰고 두번째 프로세스에서는 GPU3을 쓰고, 세번째 프로세스에서는 GPU0을 쓴다는 것을 알 수 있다.
* node : 컴퓨터의 갯수. 아래 코드는 단독 머신이므로 이 개념이 쓰이지는 않았다.
* world_size : 여러 컴퓨터에 같은 GPU갯수가 달려 있다고 가정 할 때, (각 컴퓨터에 달린 GPU 갯수) * (컴퓨터 갯수)라고 할 수 있다. 즉, 모델을 훈련하는 데에 필요한 총 GPU갯수.
* nproc_per_node : 위의 os.environ과 반드시 일치 해야한다. 이게 가장 애먹었던건데 기본 구글링에서는 그냥 한 서버를 다 쓰는 것을 가정해서 이게 그냥 컴퓨터에 달린 GPU갯수라고 명시해 놨다. 하지만 몇번 GPU를 쓸것인지를 정확히 명시 하려면 이것을 os.environ["CUDA_VISIBLE_DEVICES"]에 딸린 숫자 갯수와 일치해야 한다. 이건 직접 보고 그때 그때 생각해서 기입하자.
각 GPU마다 프로세스가 독립적으로 생성되어 돌아간다고 생각하자.

DistributedDataparallel을 사용 할 경우 반드시 알아야 할 것
1. argparser에 local_rank를 추가
2. gpu로 보낼때 반드시 local_rank에 맞춰 보내기
3. DistributedSampler 추가
4. world_size는 별개이지만 GPU총 갯수를 헷갈리지 않게 하기 위해 넣는다.
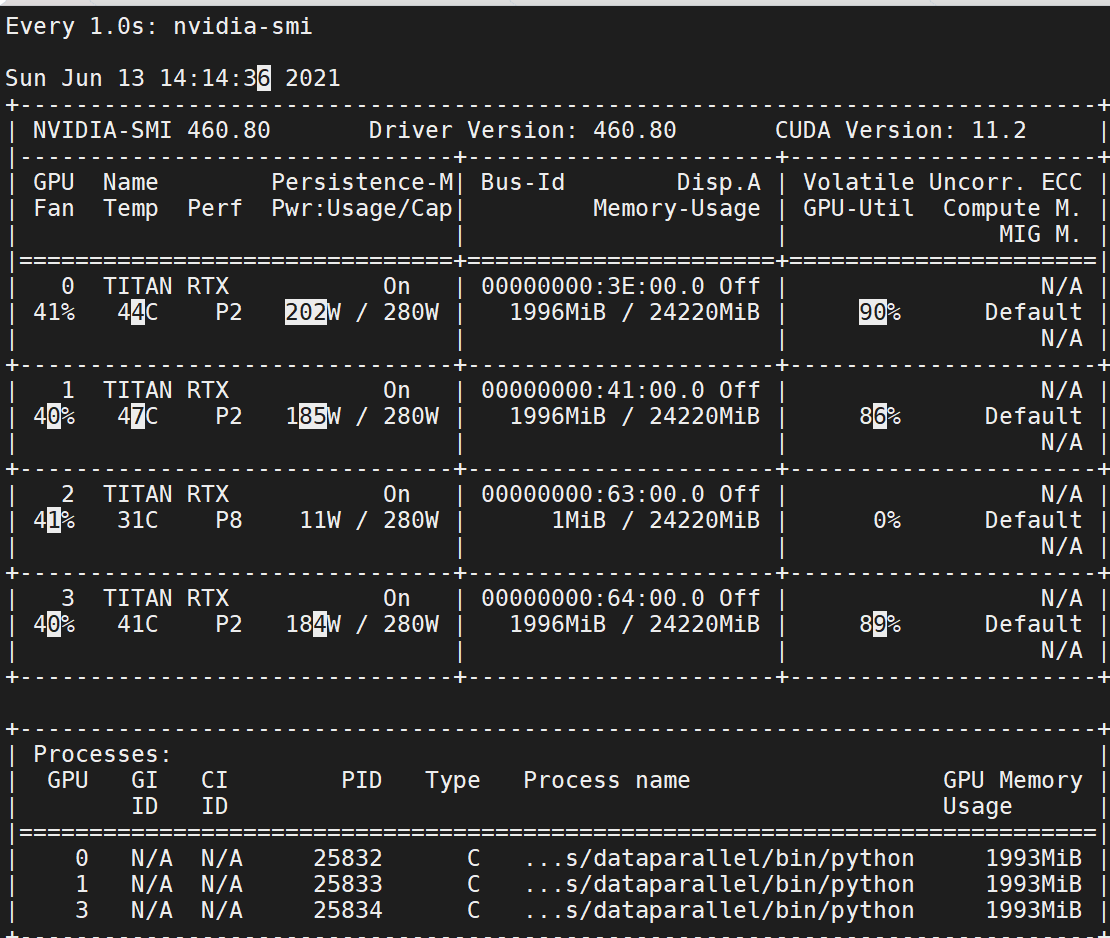
결과를 보면 아까와 달리 전부다 같은 양의 메모리를 차지하는 것을 볼 수 있다. 하지만 PID는 모두 다르다. 즉, 개별적으로 실행되고 있는 코드들이다. 아까보다 훨씬 더 많은 메모리를 차지하는 것을 볼 수 있다.
3. Distributed DataParallel (apex)
예제 코드는 쉬운 코드라 잘 돌아가는 것을 확인할 수 있는데 토치에서 지원하는 Distribute는 모델에서 안 쓰는 매개변수가 있을 경우 오류가 뜬다고 한다. 그래서 추가적으로 알아본 것.
먼저 https://github.com/NVIDIA/apex 에서 파일들을 다 다운 받는다. 오피셜 코드에서 알려주는

이 명령어를 사용해도 되지만 내 경험상 이걸로 설치하면 무조건 apex폴더에 들어가서 import apex를 해야 돌아간다. 따라서 나는 그냥 압축파일을 다운로드하고 안에 내용물을 내 패키지에 그대로 집어 넣는다. 그다음 3번째 명령어 실행하면 내가 지금 짜는 코드에서 임포트가 된다.

방법은 토치의 DistributeDataParallel과 같다. 무조건 local_rank를 parser에 집어넣고 프로세스 그룹을 initialize한 다음 apex에서 DDP로 묶어준다. 실행 명령어도 토치와 같다.

하지만 문제는 실제 KD 이미지넷 코드를 돌릴 경우 num_workers=0아니면 only to child process 에러가 뜬다. 아직 방법을 찾지는 못함.
4. apex + amp
amp는 mixed_precision이라는 것을 사용하여 쓸데없는 계산 량을 줄이고 성능 차이는 거의 안나게 하는 패키지.

위의 코드에서 opt_level만 바꾸면 된다. 알아본 바로는 O1을 가장 많이 쓴다고 하는데 정확히 무슨 차이가 있는지는 모르겟다. 또한 내 실험 결과에서는 O1이 기존보다 더 느리게 떳다.
5. 실행 속도 비교
위의 코드를 돌렸을때 20iter마다 찍힌 실행 시간.
Dataparallel : 5.6 -> 9.2 -> 12.8 -> 16.3 -> 20.4
nn.DistDataparallel: 0.4 -> 2.5 -> 4.6 -> 6.7 -> 8.7
apex: 0.9 -> 3.3 -> 5.7 -> 8.0 -> 10.3
apexO1: 0.4 -> 3.9 -> 5.7 -> 8.0 -> 10.3
apexO2: 0.4 -> 2.8 -> 5.3 -> 7.8 -> 10.4
apexO3: 0.3 -> 2.1 -> 3.8 -> 5.5 -> 7.2 apex에서 만든것끼리 쓴것이 제일 빠른듯.
nn.DistDataparallel O1: 0.4 -> 3.3 -> 6.5 -> 9.6 -> 12.8
nn.DistDataparallel O2: 0.4 -> 2.8 -> 5.5 -> 8.2 -> 10.5
nn.DistDataparallel O3: 0.3 -> 2.2 -> 4.0 -> 6.0 -> 8.0
'파이토치&텐서플로우&관련코딩' 카테고리의 다른 글
(미결) GAN학습 할 때 G부터? D부터? + 추론시간은 모델 크기에 비례? (0) 2021.05.31 SoftmaxGAN에서 모델 그래프 구조 공부 (0) 2021.05.05 torch gradient 계산 정리 (0) 2021.04.28 LR Schedulr 정리 (0) 2021.04.25 view vs reshape (0) 2021.04.23