-
RNN 차원 계산파이토치&텐서플로우&관련코딩 2020. 11. 12. 20:02
예를 들어
X = [batch_size, seq_length, input_dim] , 일때 hidden_dim, output_dim 이 존재 한다고 하면,
X 를 x_1, x_2, ..., x_seq_length로 나눈뒤, h가 처음부터 들어감.
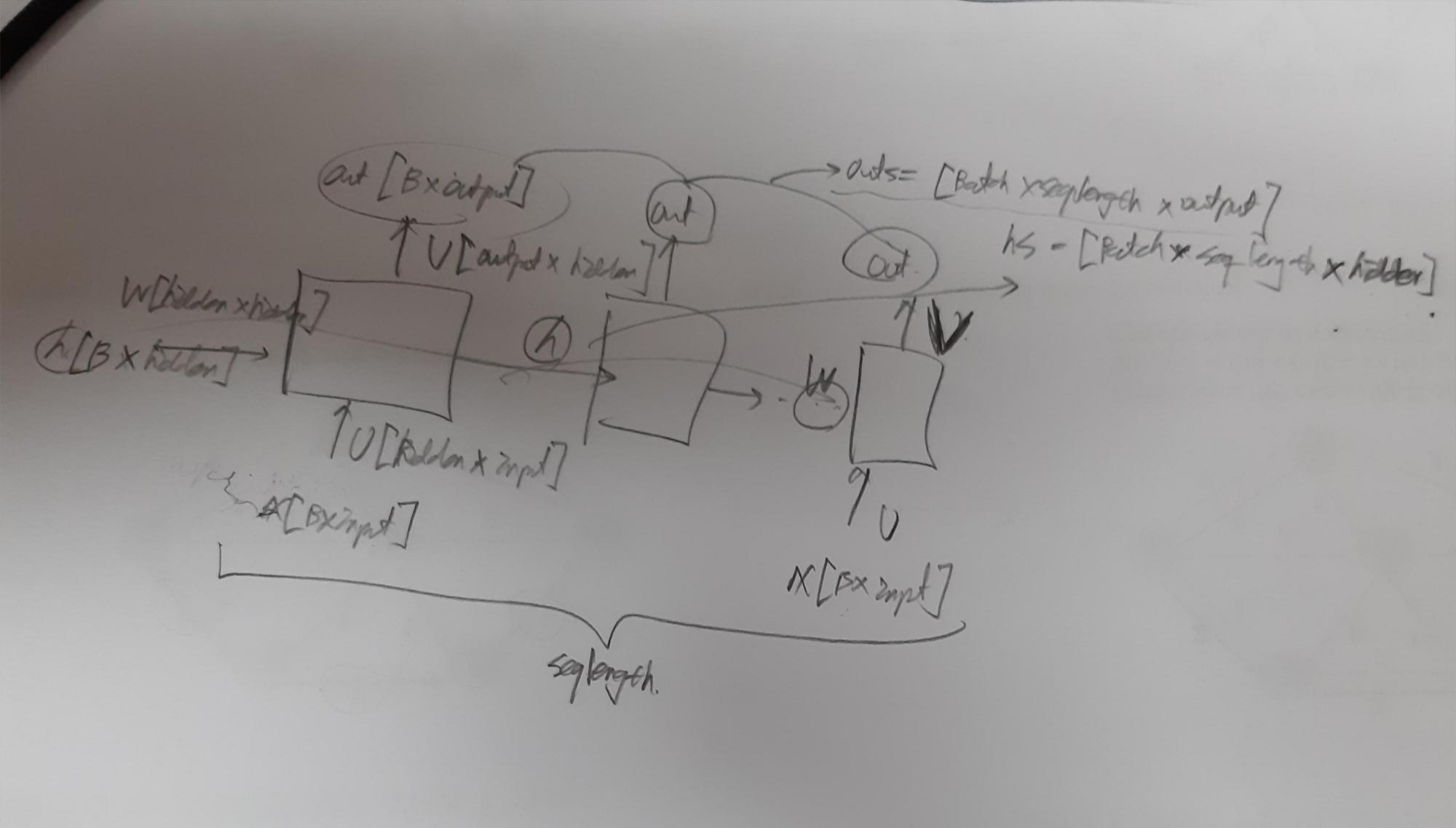
그림 참조하면 W, U, V는 x가 seq_length개가 한 epoch동안 돌 때 고정되어있고,
실제로 파이토치에서 Linear을 계산 할때는 예를 들어
Linear(10,20)(W)이고 입력(X)이 [16 * 10]이면 결과는 [16*20]일텐데 Linear의 weight는 [20*10]이고, X(W^T)로 계산된다
또한 예를 들어 책의 문장들을 훈련 할 때, "asdfkhgasdfkhjgaskjhfgasdjfasdhjkfg"가 있으면 먼저 batch 단위로 나누는 generator(yield 사용)를 만들어 for문에서 하나씩 뱉어내고, 그 다음에 원핫인코딩을 하는데 왜 먼저 모든 문장을 원핫인코딩 하지 않냐면 보통 문자 데이터의 크기는 매우 방대하기 때문에 이 전체를 원핫인코딩 하는것이 쉽지 않다.

위의 그림처럼 처음 훈련 데이터 문자열의 길이를 1985223라고 하면, batch_size = 10, seq_len = 50이라고 할 때, 500단위만큼 잘려 나가야 쓸수 있다. 즉, 이미지를 처리할 때에는 전체 이미지 갯수와 배치사이즈만 고려하면 되었지만, 무낮열에서는 seq_len라는 새로운 변수가 등장하였으므로 배치사이즈와 seq_len두개를 곱한 값의 배수만을 총 배치로 고려해야한다. 따라서 초기 입력데이터 arr를 batch_size * seq_len의 최대배수까지 잘라내고(1985000) 이를 (10, 198500)으로 reshape한 뒤, seq_len만큼 잘라낸다. 다시 말해서, batch size만큼 reshape, seq_len 만큼 잘라내므로 두 수의 최소공배수 만큼의 배수가 필요하다.
BATCH_FIRST 안쓸때
입력은 [SEQ_LEN*BATCH_SIZE]로 들어감. nn.Embedding(num_words, embedding_dim)에서 num_words는 입력의 단어 갯수를 뜻함. 이건 실제로는 행렬에 영향을 안주고 임베딩의 성능을 결정. 임베딩 후에는 [SEQ_LEN*BATCH_SIZE*HIDDEN_SIZE]으로 나온다.이 때, RNN으로 들어가기 위해 BATCH_FIRST가 FALSE이므로 그대로 들어간다. 즉 , RNN으로 들어가기 직전의 차원은 [SEQ_LEN * BATCH_SIZE * EMBEDDING_DIM]이고, 보통 EMBEDDING_DIM은 HIDDEN_DIM과 같다. 그래야 들어갈수 있기 때문에.
'파이토치&텐서플로우&관련코딩' 카테고리의 다른 글
loss.backward(retain_graph=True)의 필요성 & GAN 학습할때 (0) 2021.01.05 파이토치 비전에서의 shape 의미 (0) 2021.01.05 resnet 레이어 custom으로 변경하기 (0) 2020.12.30 model train(), eval() (0) 2020.12.13 RNN (0) 2020.11.27